@[TOC](Spring Cloud Sleuth)
1. 简介
在大规模的分布式系统中,一个完整的系统是由很多种不同的服务来共同支撑的。不同的系统可能分布在上千台服务器上,横跨多个数据中心。一旦系统出问题,此时的问题定位就比较麻烦。
分布式链路追踪:
在微服务环境下,一次客户端请求,可能会引起数十次、上百次的服务之间的调用。一旦请求出问题了,我们需要考虑很多东西:
- 如何快速定位问题?
- 如何快速确定此次客户端调用,都涉及到哪些服务?
- 到底是哪一个服务出问题了
要解决以上问题,就涉及到分布式链路追踪。
分布式链路追踪系统主要用来跟踪服务调用记录的,一般来说,一个分布式链路追踪系统,有三个部分:
Spring Cloud Sleuth 是Spring Cloud 提供的一套分布式链路追踪系统。
trace : 从请求到达系统开始,到给请求作出响应,这样一个过程称为 trace
span : 从每次调用服务时,埋入的一个调用记录,称为 span
annotation : 相当于 span 的语法,描述 span 所处的状态。
2. 简单应用
新创建一个项目,引入如下依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
|
接下来创建 HelloController ,打印日志测试:
@RestController
public class HelloController {
private static final Log log = LogFactory.getLog(HelloController.class);
@GetMapping("/hello")
public String hello(){
log.info("hello Spring Cloud Sleuth!!!");
return "hello Spring Cloud Sleuth";
}
}
|
给服务配置名字,在输出的日志中会体现出来:
spring.application.name=first-sleuth
|
然后启动服务,访问 :http://127.0.0.1:8080/hello,打印日志,如下图: 右边标记的就是 Spring Cloud Sleuth 的输出。

在定义两个接口,在 hello2 中调用 hello3 ,形成调用链:
@GetMapping("/hello2")
public String hello2() throws InterruptedException {
log.info("hello 2");
Thread.sleep(500);
return restTemplate.getForObject("http://127.0.0.1:8080/hello3",String.class);
}
@GetMapping("/hello3")
public String hello3() throws InterruptedException {
log.info("hello 3");
Thread.sleep(500);
return "hello 3";
}
|
访问 http://127.0.0.1:8080/hello2,如下:

一个 trace 由多个 span 组成,一个 trace 相当于就是一个调用链,而一个 span 则是这个链中的每一次调用过程。
2.1 异步任务
2.1.1 Spring Cloud Sleuth 中也可以收集到异步任务中的消息
开启异步任务:
@SpringBootApplication
@EnableAsync
public class SleuthApplication {
public static void main(String[] args) {
SpringApplication.run(SleuthApplication.class, args);
}
@Bean
RestTemplate restTemplate(){
return new RestTemplate();
}
}
|
创建一个 HelloService ,提供一个异步任务方法:
@Service
public class HelloService {
private static final Log log = LogFactory.getLog(HelloController.class);
@Async
public String backgroundFun(){
log.info("backgroundFun!!!");
return "backgroundFun";
}
}
|
然后在 HelloController 中调用异步任务方法:
@GetMapping("/hello4")
public String hello4() {
log.info("hello 4");
return helloService.backgroundFun();
}
|
启动项目,访问 /hello4 测试,Sleuth 也打印日志了,如下图:

总结: 在异步任务中,异步任务是相同的 traceId ,不同的 spanId。
2.1.2 Spring Cloud Sleuth 中也可以手机设定定时任务
首先开启定时任务:
@SpringBootApplication
@EnableAsync
@EnableScheduling
public class SleuthApplication {
public static void main(String[] args) {
SpringApplication.run(SleuthApplication.class, args);
}
@Bean
RestTemplate restTemplate(){
return new RestTemplate();
}
}
|
然后在 HelloService 中添加定时任务,去调用 backgroun 方法。
@Scheduled(cron = "0/10 * * * * ?")
public void sche1(){
log.info("start:");
backgroundFun();
log.info("end:");
}
|
然后访问 /hello4 接口测试,如下:
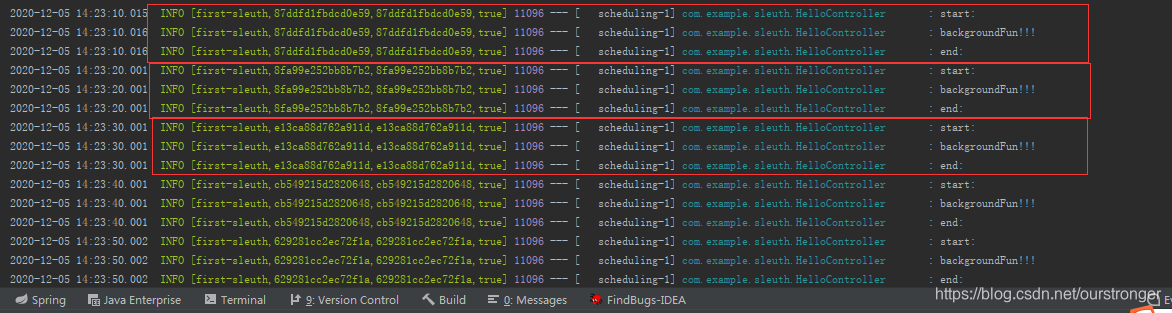
总结: 在定时任务中,每次定时任务都会产生一个新的 Trace ,并且在调用过程中 spanId 都是一致的,这点和普通的调用不一样。
3. Zipkin
Zipkin 本身是 Twitter 公司开源的分布式追踪系统。
Zipkin 分为 server 端和 client 端, server 用来展示数据, client 用来收集 + 上报数据。
3.1 准备工作
Zipkin 要先把数据存储起来,这里我们使用 Elasticsearch 来存储,所以,首先安装 es 和 es-head。这里假设 docker 已经安装并启动。
es 安装命令:
docker run -d --name elasticsearch -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:7.1.0
|
可视化工具有三种安装方式:
- 直接下载软件安装
- 通过 docker 安装
- 安装 Chrome / Firefox 插件 【这里采用第三种方式,插件名称:ElasticSearch Head】
然后安装 RabbitMQ
Zipkin 安装:
docker run -d -p 9411:9411 --name zipkin -e ES_HOSTS=192.168.1.132 -e STORAGE_TYPE=elasticsearch -e ES_HTTP_LOGGING=BASIC -e RABBIT_URI=amqp://guest:guest@192.168.1.132:5672 openzipkin/zipkin
|
- ES_HOSTS :es 的地址
- STORAGE_TYPE :数据存储方式
- RABBIT_URI : 要连接的 rabbitMQ 地址
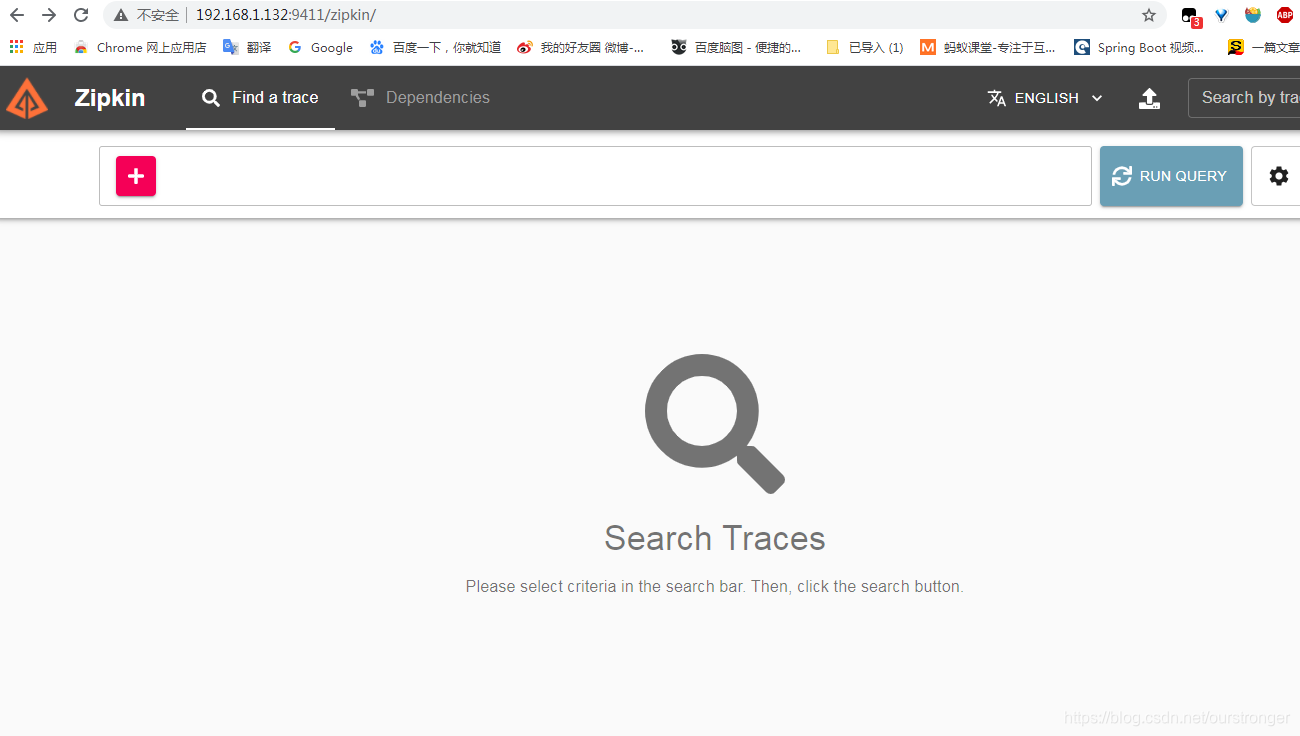
安装完成后,浏览器访问:http://192.168.1.132:9411/zipkin/ ,如下图: 表示安装成功。
3.2 实践
新建项目,添加如下依赖:
创建成功后,配置 zipkin 和 rabbitmq:
spring.application.name=zipkin01
# 开启链路追踪
spring.sleuth.web.client.enabled=true
# 配置采样比例,默认为 0.1
spring.sleuth.sampler.probability=1
# zipkin 地址
spring.zipkin.base-url=http://192.168.1.132:9411
# 开启 zipkin
spring.zipkin.enabled=true
# 追踪消息的发送类型
spring.zipkin.sender.type=rabbit
spring.rabbitmq.host=192.168.1.132
spring.rabbitmq.port=5672
spring.rabbitmq.username=guest
spring.rabbitmq.password=guest
|
接下来提供一个测试的 Controller:
@RestController
public class HelloController {
private static final Logger logger = LoggerFactory.getLogger(HelloController.class);
@GetMapping("/hello")
public String hello(String name){
logger.info("zipkin01-hello");
return "hello" + name +"!";
}
}
|
然后再创建一个 zipkin02 ,和 zipkin01 的配置基本一致,修改 zipkin02 的配置文件:
spring.application.name=zipkin02
# 开启链路追踪
spring.sleuth.web.client.enabled=true
# 配置采样比例,默认为 0.1
spring.sleuth.sampler.probability=1
# zipkin 地址
spring.zipkin.base-url=http://192.168.1.132:9411
# 开启 zipkin
spring.zipkin.enabled=true
# 追踪消息的发送类型
spring.zipkin.sender.type=rabbit
spring.rabbitmq.host=192.168.1.132
spring.rabbitmq.port=5672
spring.rabbitmq.username=guest
spring.rabbitmq.password=guest
server.port=8081
|
添加RestTemplate , 修改 zipkin02 的 Controller :
@RestController
public class HelloController {
private static final Logger logger = LoggerFactory.getLogger(HelloController.class);
@Autowired
RestTemplate restTemplate;
@GetMapping("/hello")
public void hello(String name){
String s = restTemplate.getForObject("http://127.0.0.1:8080/hello?name={1}", String.class, "javaboy");
logger.info(s);
}
}
|
接下来分别启动 zipkin01 和 zipkin02 ,启动成功后,访问:http://127.0.0.1:8081/hello?name=qqq,查看控制台, traceId 和 spanId 均已输出。然后浏览器访问:
http://192.168.1.132:9411/zipkin/, 所有的信息都已经可视化的展示出来了。如下图:
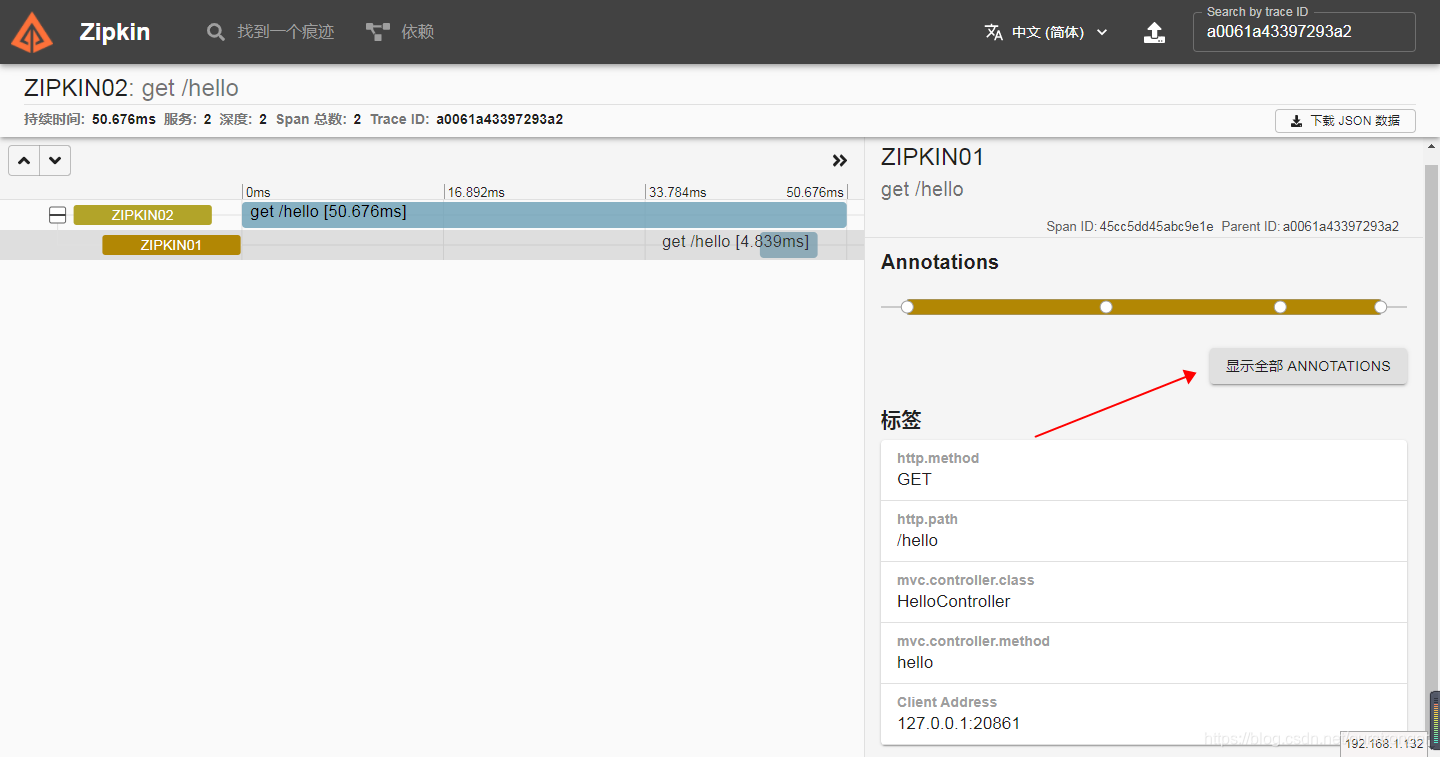
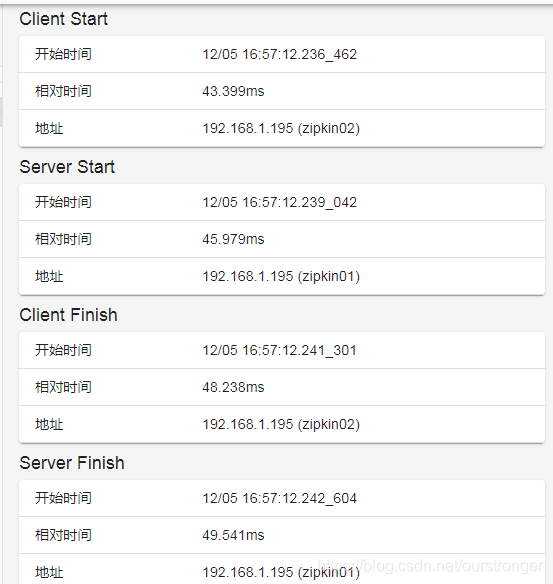
以上是数据的可视化展示,那么数据本身在哪里呢?打开Chrome的 Elasticsearch Head 插件,访问: http://192.168.1.132:9200/ 连接,如下图:
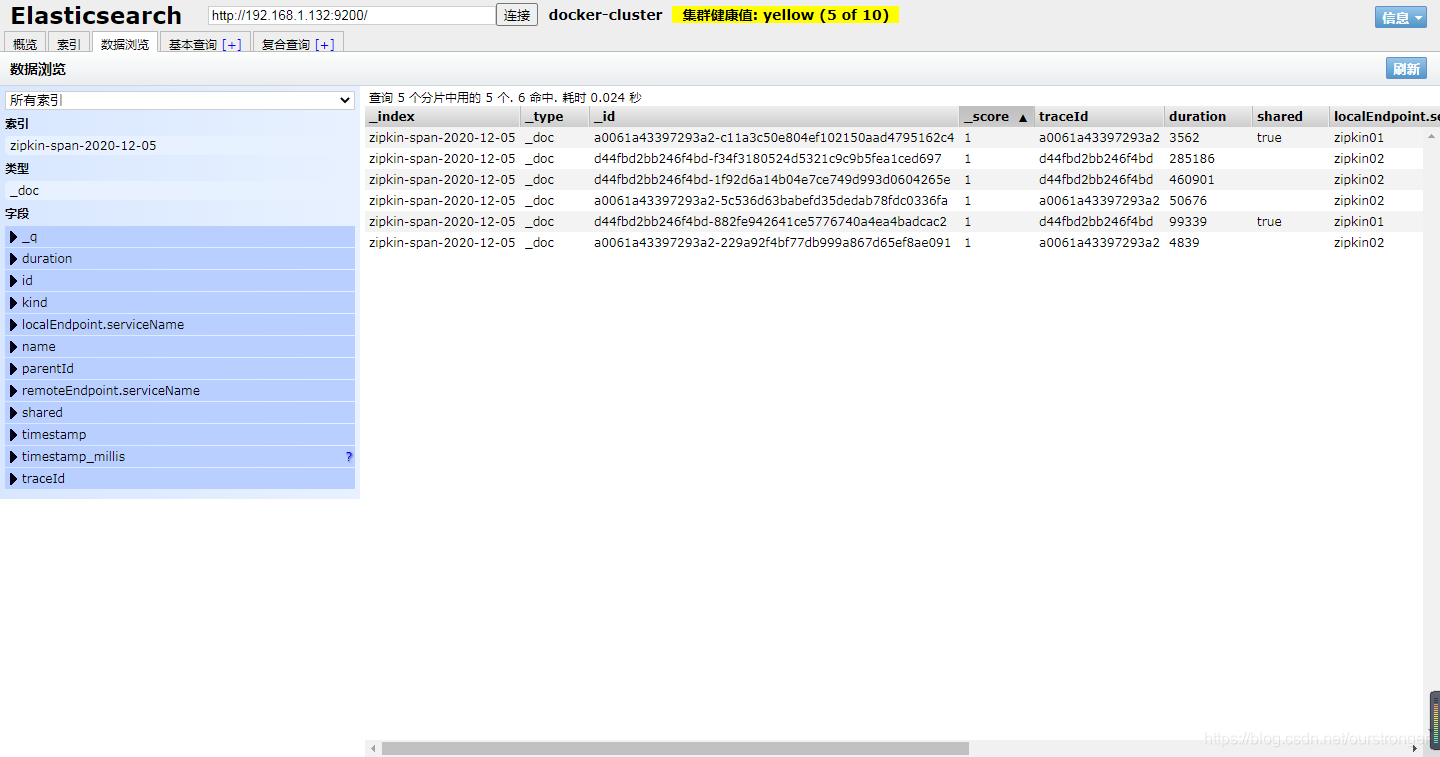
然后访问 : http://192.168.1.132:15672/ ,登陆后,发现 zipkin 已经添加至 rabbitMQ 队列中。
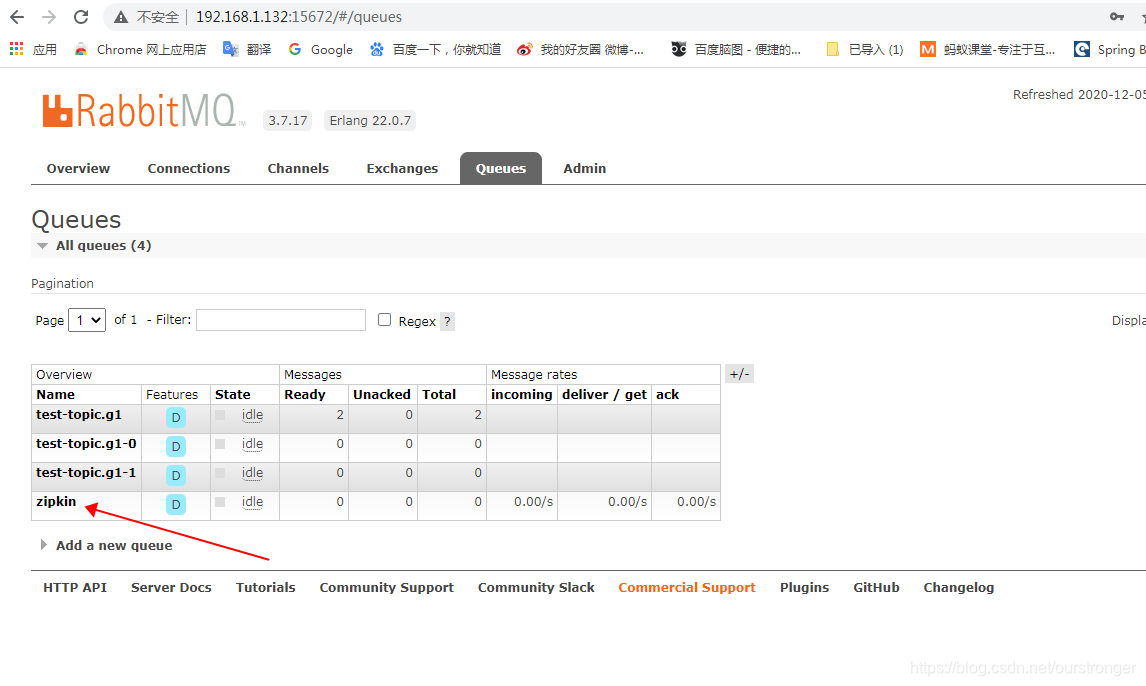
此时,这三个已经连通起来了。数据从 rabbitmq 传递到 es 上面去,es再可视化展示出来。
项目地址:**https://github.com/astronger/springcloud-simple-samples**

